
Attack of the Clones – The War on Code Duplication
April 1, 2025
I remember the clone war. Not that one, but the war on code duplication. Wasn’t too long ago, and still going strong.

Everyone who’s written a bit of code, knows we shouldn’t duplicate code. It’s like the opening session of day 2 of software school.
And we all know why – maintenance. When we make changes in the code (and we will make changes in the code), we’ll have to go into each clone of that code. And that’s if we remember where we left the clones.
It’s easier to extract the duplicates into one place, and make the changes in one place. Like I said, opening session material.
Code Duplication 101
While we all know this, we sometimes don’t follow that rule. For example, with automated tests, once we have a passing test, it’s easy to copy that test, and change it a bit for the next case. When the first test is for the “if” part, the second one for the “else”, for example.
We know it’s wrong. We also have a way out – once we copy the test, and our tests are all passing, we promise to do the extraction. We’re sure of that.
Only, now we have two tests passing. Who thinks about the extraction? We just move on to the next test. Which is, of course, another semi-clone.
More tests, more duplication. Whatever we clone, we get more of it. That’s how cloning works.
If we clone ugly code, we get many incarnations of it. If we extract, we get more usage of the extraction, which is usually less lines of code. But should we extract piece of code every time?
A Cloning Recipe
I have a rule for myself. The rule of 3 – The third duplication requires refactoring.
Let’s see an example. Here’s my first test – it’s passing already.

I’m moving to the next test, copying and modifying it. Now I have two tests.

Now that both tests are passing, I can already extract it.
Wait! I Sense The Dark Side Presence
This would be a good time to talk about the dark side of code duplication removal. Well, dark-ish.
Look at those tests. They each tell their own story. The details are there. We say they are readable, because the whole story is in there. We don’t need to go to other places to get more information.
Which is very helpful when one of those guys fails. My job at that point, would be to figure out the problem and solve it as quickly as possible. If I have all the information in front of me, I’ll get there faster.
This is something that applies more to tests, rather than production code. Tests usually have a beginning and an end. We can move common code to other functions (for example, to a beforeEach function). We eliminate the clones, but the beginning can be somewhere up in the file (sometimes another file), while I’m looking at a test at the bottom of it. Readability can suffer from extractions.
So I stretch it. That’s why I count to 3. In next test, it’s becoming too much.
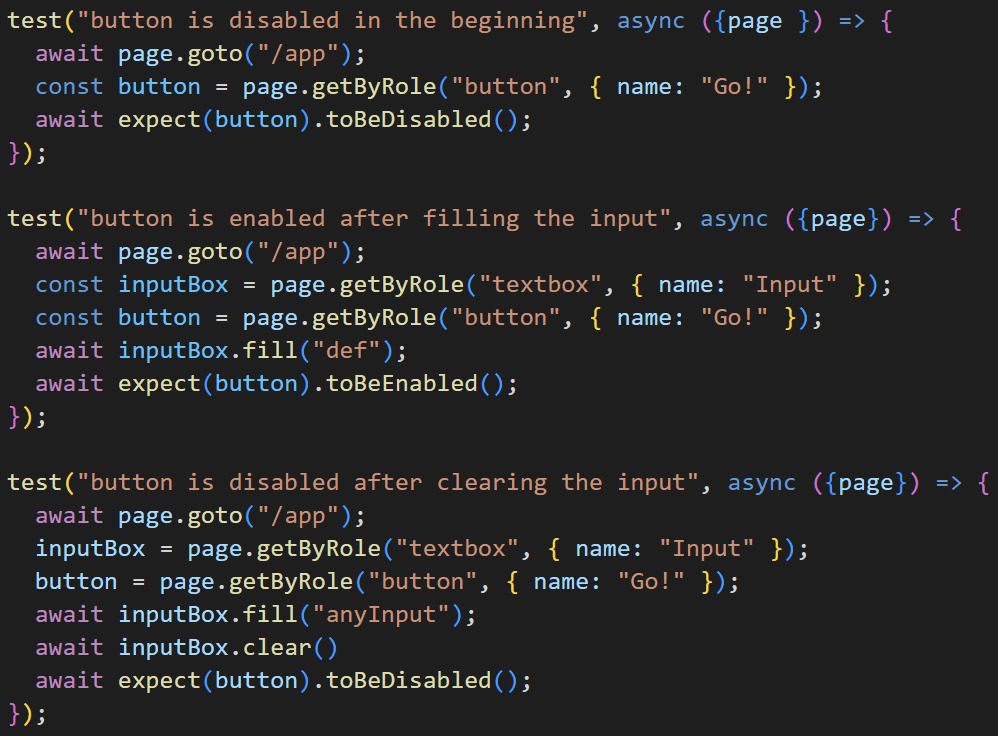
Surrounded by clones. So refactor.

Looks better. At this point I decided that that cloning has run its course.
Duplication has advantages – short-term progress, and some readabilty. However, these gains are usually offset by long-term maintenance. We’d rather invest now, for quick progress later.
If you want to go back to the principles of good software, production or automation, check out my Clean Code workshop. There’s nothing like it.


